转自:http://blog.csdn.net/hinyunsin/article/details/6401854
最近写了一个网络文件传输模块,为了让这个模块具有更好的移植性,我尽量使用C标准IO API来编写代码。模块是在Linux下面写的,一点问题都没有。但是昨天把客户端的代码移植到了windows上,结果就出现了一个很奇怪的问题,客户端从服务器端下载的数据保存在本地总是比服务器上的原始文件要大,下载的二进制文件(比如zip文件)总是被破坏,而下载的文本文件却看不出任何问题。看了半天代码,一直把注意力放在fread和fwrite函数上,怎么都看不出什么问题,Linux下测试也一点问题没有。于是我就又用fopen,fread,fwrite函数写了一个文件复制的小程序,代码如下:
#include #define BUF_SIZE 0x2000 const char src[]="from"; const char dest[]="to"; int main(int argc,char **argv){ FILE *fp,*fp2; char buf[BUF_SIZE]; int num; fp=fopen(src,"r"); fp2=fopen(dest,"w"); num=fread(buf,sizeof(char),BUF_SIZE,fp); while(num>0){ fwrite(buf,sizeof(char),num,fp2); num=fread(buf,1,BUF_SIZE,fp); } fclose(fp); fclose(fp2); return 0; } 结果显示,复制的文件依然比原始文件要大。
于是在网上用关键字"fread fwrite 复制 文件 大小不一"去查了,发现有两个人也说大小不一,但是他们跟我不一样的是,他们的fwrite函数第3个参数不是这里的num,而是BUF_SIZE,这样 很显然得到的结果一般会比原始的大,因为最后一个数据包读取的大小很可能比BUF_SIZE要小。查了很久知道,突然看到一个人的代码上fopen函数是 采用二进制打开的:fopen("xxx","wb"),于是我尝试着改成二进制,一试,居然成功了!!!
于是就查阅MSDN,上面说:
Open in binary (untranslated) mode; translations involving carriage-return and linefeed characters are suppressed.
If t or b is not given in mode, the default translation mode is defined by the global variable _fmode.
If t or b is prefixed to the argument, the function fails and returns NULL.
意识是:使用二进制模式打开,翻译换行符的时候会进行压缩。具体是什么意思还不太明白,于是又到网上特地搜了一下fopen中二进制和文本的区别。中说的很不错:
在学习C语言文件操作后,我们都会知道打开文件的函数是fopen,也知道它的第二个参数是 标志字符串。其中,如果字符串中出现'b',则表明是以打开二进制(binary)文件,否则是打开文本文件。
那么什么是文本文件,什么是二进制文件呢? 可能大多数人都没有仔细考虑过。
在Windows和DOS系统中,狭义的文本文件是指扩展名为txt的文件。实际上,那些没有规定格式的,由可理解的的ASCII以及 其他编码文字组成的文件都是文本文件,如C源程序文件,HTML超文本,XML。除此之外的其他文件都是二进制文件,如Word文件DOC,图象格式文件 JPG。
但是,所谓使用fopen标志打开文本文件与二进制文件的说法并不准确。正确的说法应该是--以文本方式和二进制方式打开文件。因为我们用两种方式都可以任意的文件。
即使这样,为什么还要区分两种方式呢?
这是因为这两种方式在读写文件时的操作是不一样的。
二进制方式很简单,读文件时,会原封不动的读出文件的全部內容,写的時候,也是把內存缓冲区的內容原封不动的写到文件中。
而文本方式就不一样了,在写文件时,会将换行符号CRLF(0x0D 0x0A)全部转换成单个的0x0A,并且当遇到结束符CTRLZ(0x1A)时,就认为文件已经结束。相应的,写文件时,会将所有的0x0A换成0x0D0x0A。
所以,若使用文本方式打开二进制文件时,就很容易出现文件读不完整,或內容不对的错误。即使是用文本方式打开文本文件,也要谨慎使用,比如复制文件,就不应该使用文本方式。
要特別注意的是,上面这样的说法仅适用于DOS和Windows系统。在Unix和其他一些系统中,沒有文本方式和二进制方式的区分,使不使用'b'标志都是一样的。这是由于不同操作系统对文本文件换行符的定义,和C语言中换行符的定义有所不同而造成的。
如上文已提到,DOS和Windows系统使用CRLF(0x0D 0x0A)双字节作为文本文件换行符,而Unix文本文件的换行符只有一个字节LF(0x0A)为。在C语言中,也是以LF即'/n'为换行符。
由于DOS/Windows定义的换行符和C语言的不一致,C语言的标准输入输出函数适行读写文本文件时,就适行了CRLF->LF的转换。而Unix的定义和C语言的是一样的,就不必转换了。
那么,为什么會有定义不一致的情况呢,这纯属历史原因。当初C是在Unix上发展的,对换行的定义自然就一样了。其后C被引入到DOS 系统,为了使原有的C程序能不加修改的读写DOS的文本文件,所以就在文件读写上做了修改。随着DOS/Windows成为主流平台,这个当初为了兼容而 做的修改給众多的C语言开发者添了这样一个小小的麻烦。
从这篇文章中,看出,我从服务器上下载数据的并写入文件的时候,所有0x0A的数据通通被windows按照0x0Dx0A的方式写入了,结果数据自然就变大了!
我做了一个实验,在Linux下面输入了几千个回车符,这些回车符以0x0A的方式写入文件中,我使用上面的程序对它进行了复制,使用二进制方式打开,如下图:
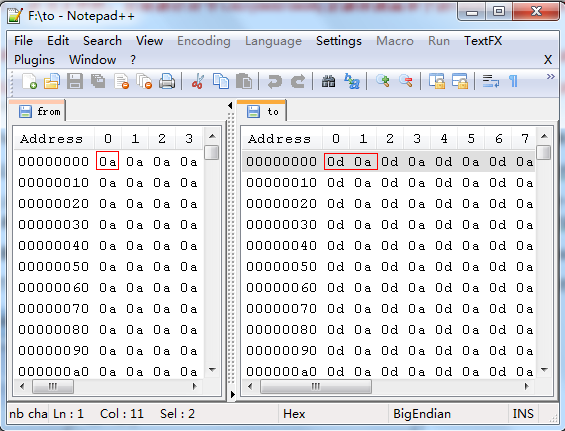
很明显,所有的0x0A都被替换成了0x0D0x0A,文件大小翻倍了!

于是乎前面的每个问题都得到了解释,文件变大,文本文件看不出问题(反正编辑器自动给你换行了),二进制文件被破坏,Linux下没有问题(不区分文本和二进制),windows有!
我们把代码修改为二进制模式,于是整个世界回归了正常轨道!
#include #define BUF_SIZE 0x2000 const char src[]="from"; const char dest[]="to"; int main(int argc,char **argv){ FILE *fp,*fp2; char buf[BUF_SIZE]; int num; fp=fopen(src,"rb"); fp2=fopen(dest,"wb"); num=fread(buf,sizeof(char),BUF_SIZE,fp); while(num>0){ fwrite(buf,sizeof(char),num,fp2); num=fread(buf,1,BUF_SIZE,fp); } fclose(fp); fclose(fp2); return 0; }